
ESTADISTICA DESCRIPTIVA. LAS SEIS CARACTERÍSTICAS DE LOS DATOS
Mucio Osorio
En estas notas se estudian las herramientas estadísticas esenciales en el análisis descriptivo de los datos y que estan basadas en el artículo “The Six Characteristics of a Dataset”. Para ejecutar un pedazo de código (Chunk) solo dar “clic” en el boton verde de Ejecutar (Run) o situando el cursor en la linea a ejecutar y presionar Ctrl+Shift+Enter.
En el proceso Estadístico, una vez que se han conseguido los datos lo primero que tendremos que hacer es analizarlos de diferentes maneras. Las siguientes seis características son un buen punto de partida.
The Old Faithful Dataset

Geyser Old Faithful
x = faithful
Si se requiere Información sobre los datos old faithful solo escriba ?faithful
## starting httpd help server ... done1. Localización de los datos.
Con éstas medidas se pretende tener una idea de la ubicación de los datos en algún lugar de los números reales. Es importante dar la posición del dato más pequeño, del dato más grande, de lo que en Estadística se conoce como la tendencia central de los datos y los cuantiles (que dan otras ubicaciones incluidas las centrales).
En R, éstas medidas pueden obtenerse de diversas maneras a través de los distintoss paquetes, ya sea de manera individual o como parte de un resumen. En este trabajo se usan solo paquetes del sistema base de R y en el caso de que se use algún otro paquete se instalará para su uso.
Mínimo. Es el valor más pequeño de los datos, si se encuentran ordenados es muy fácil ubicarlo.
El tiempo mínimo que tarda una erupción es 1.6 minutos.eyJsYW5ndWFnZSI6InIiLCJzYW1wbGUiOiJtaW4oZmFpdGhmdWwkZXJ1cHRpb25zKVxubWluKGZhaXRoZnVsJHdhaXRpbmcpIn0=Máximo. El valor más grande de los datos.
eyJsYW5ndWFnZSI6InIiLCJzYW1wbGUiOiJtYXgoZmFpdGhmdWwkZXJ1cHRpb25zKVxubWF4KGZhaXRoZnVsJHdhaXRpbmcpIn0=Tendencia central
3.1 ModaEs el dato que más veces aparece
eyJsYW5ndWFnZSI6InIiLCJzYW1wbGUiOiJ0YWJsZShmYWl0aGZ1bCRlcnVwdGlvbnMpXG50YWJsZShmYWl0aGZ1bCR3YWl0aW5nKSJ93.2 MedianaLa mediana corresponde al dato que se ubica justo a la mitad, cuando se ordenan
eyJsYW5ndWFnZSI6InIiLCJzYW1wbGUiOiJtZWRpYW4oZmFpdGhmdWwkZXJ1cHRpb25zKVxubWVkaWFuKGZhaXRoZnVsJHdhaXRpbmcpIn0=3.3 Media
La media aritmética es la medida de tendencia central más conocida. La mayor parte de la gente la llama el promedio. En una muestra el símbolo de la estadística de la media es \[\overline{x}\] y corresponde a la suma de todas las observaciones dividida por el número de observaciones \[\frac{\sum_{i=1}^{n}{x_i}} {n}\] .
- Cuantiles. La palabra cuantil viene de la palabra cantidad. En terminos simples, un cuantil es cuando se divide al conjunto de datos en subgrupos adyascentes de igual tamaño. Especificamente, los cuantiles reciben diferentes nombres en función de la cantidad de partes enque se divide a los datos. Por ejemplo cuando se divide a los datos en 100 partes iguales, los cuantiles se denominan percentiles y se identifican con la notación Pj (con 0<j<1) y cuando la división es en 4 partes se llaman Cuartiles y se identifican con Qk (k=1,2,3)
eyJsYW5ndWFnZSI6InIiLCJzYW1wbGUiOiJxdWFudGlsZShmYWl0aGZ1bCRlcnVwdGlvbnMpXG5xdWFudGlsZShmYWl0aGZ1bCR3YWl0aW5nKVxuIyBTaSBzZXJlcXVpZXJlIHNvbG8gdW4gY3VhbnRpbCAocG9yIGVqZW1wbG8gZWwgMTAlKVxucXVhbnRpbGUoZmFpdGhmdWwkZXJ1cHRpb25zLDAuMTApIFxuIyBzaSBzZXJlcXVpZXJlIG1cdTAwZTFzIGRlIHVuIGN1YW50aWwsIGRvbmRlIGMoMC4xMCwwLjQ1LDAuOTkpIGVzIHVuIHZlY3RvciBkZSBjdWFudGlsZXMgYSAgY2FsY3VsYXJcbnF1YW50aWxlKGZhaXRoZnVsJHdhaXRpbmcsYygwLjEwLDAuNDUsMC45OSkpICJ9Para calcular los percentiles existen varios métodos. En R, use el tipo 2 para obtener los mismos resultados que los obtenidos en clase.eyJsYW5ndWFnZSI6InIiLCJzYW1wbGUiOiJxdWFudGlsZShmYWl0aGZ1bCRlcnVwdGlvbnMsIHR5cGUgPSAyKVxucXVhbnRpbGUoZmFpdGhmdWwkd2FpdGluZywgdHlwZSA9IDIpIn0=
Dispersión o variabilidad
Estudia la distribución de los valores de la serie, analizando si estos se encuentran más o menos concentrados, o más o menos dispersos. Existen diversas medidas de dispersión, entre las más utilizadas podemos destacar las siguientes:
- Amplitud.
En R, la función diff cálcula la diferencia de dos cantidades:
- Varianza.
Mide la distancia (cuadrada) existente entre los valores de la serie y la media. Mientras más se aproxima a cero, más concentrados están los valores de la serie alrededor de la media. Por el contrario, mientras mayor sea la varianza, más dispersos están. El símbolo para representar a la varianza muestral es \[{s^2}\] y para la varianza poblacional \[{\sigma ^2}\].
\[s^2=\frac{\sum_{i=1}^{n}\left(x_i-\bar{x}\right)^2}{n-1}\]
\[\sigma^2=\frac{\sum_{i=1}^{N}\left(x_i-\mu\right)^2}{N}\]- Desviación estándar o típica.
Nótese que ni la varianza ni la desviación estándar pueden ser negativas y son cero sólo cuando todos los datos tienen el mismo valor que no es otro que el valor de la media.
Valores extremos.
Los diagramas de Caja-Bigotes (boxplots o box and whiskers) son una presentación visual que describe varias características importantes, al mismo tiempo, tales como la dispersión, la tendencia central y simetría. Tambien se usa para detectar valores atípicos (extremos).
Para su realización se representan en una caja o rectángulo los tres cuartiles (\(P_{0.25}\), \(P_{0.50}\) y \(P_{0.75}\)) y se trazan lineas hasta máximo una distancia de 1.5(P0.75-P0.25). De modo que cualquier dato o caso que no se encuentre dentro de este rango es identificado como un valor extremo.
4. Forma de los datos o distribución de frecuencias.
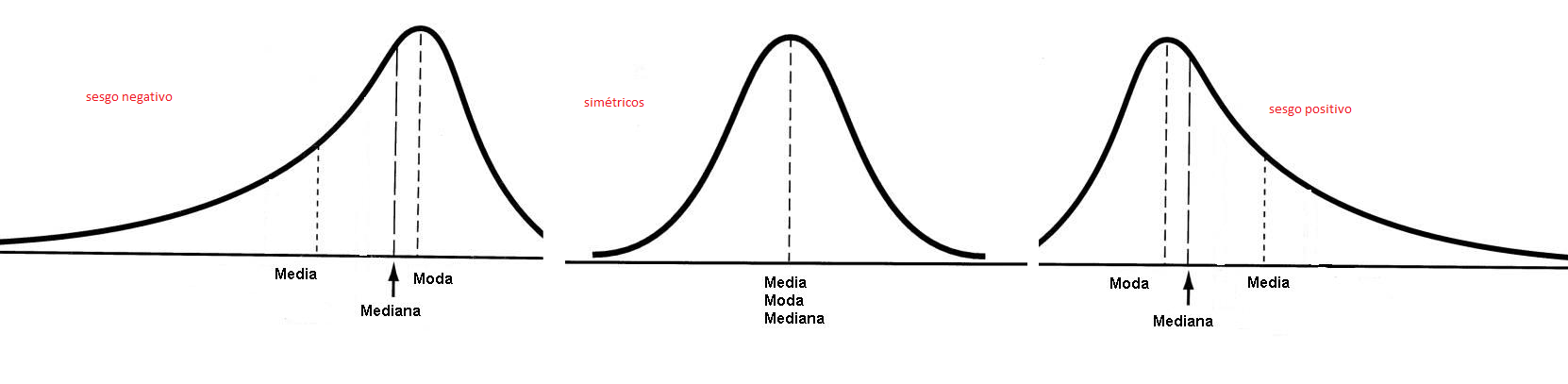
La distribución de frecuencias es el principal factor en la determinación de las medidas que mejor describen a los datos. Así que debería ser la primera característica a revisar. Normalmente, se concluye que los datos son simétricos o asimétricos (con sesgo positivo o negativo) o tambien se clasifica a los datos como unimodales, bimodales o multimodales.
Una herramienta útil para visualizar la forma de los datos es el histograma.
La relación entre la gráfica de la distribución y las medidas de tendencia central.
En distribuciones unimodales cuando la media, la moda y la mediana coinciden la distribución es simétrica.
En distribuciones unimodales cuando la media, la moda y la mediana no coinciden la distribución es sesgada.Si la media es mayor que la mediana (la media a la derecha de la mediana) entonces la distribución está sesgada a la derecha (o positivamente).
Si la media es menor que la mediana (la media a la izquierda de la mediana) entonces la distribución está sesgada a la izquierda (o negativamente)
5. Agrupamientos o clústers
La agrupación implica que los datos tienden a acumularse alrededor de ciertos valores, por ejemplo, los salarios anuales de una empresa pueden agrupars alrededor de 5000 pesos para trabajadores no calificados, 10000 pesos para trabajadores calificados y 15000 pesos para los administrativos. Los agrupamientos pueden detectarse en un histograma o un gráfico de puntos.
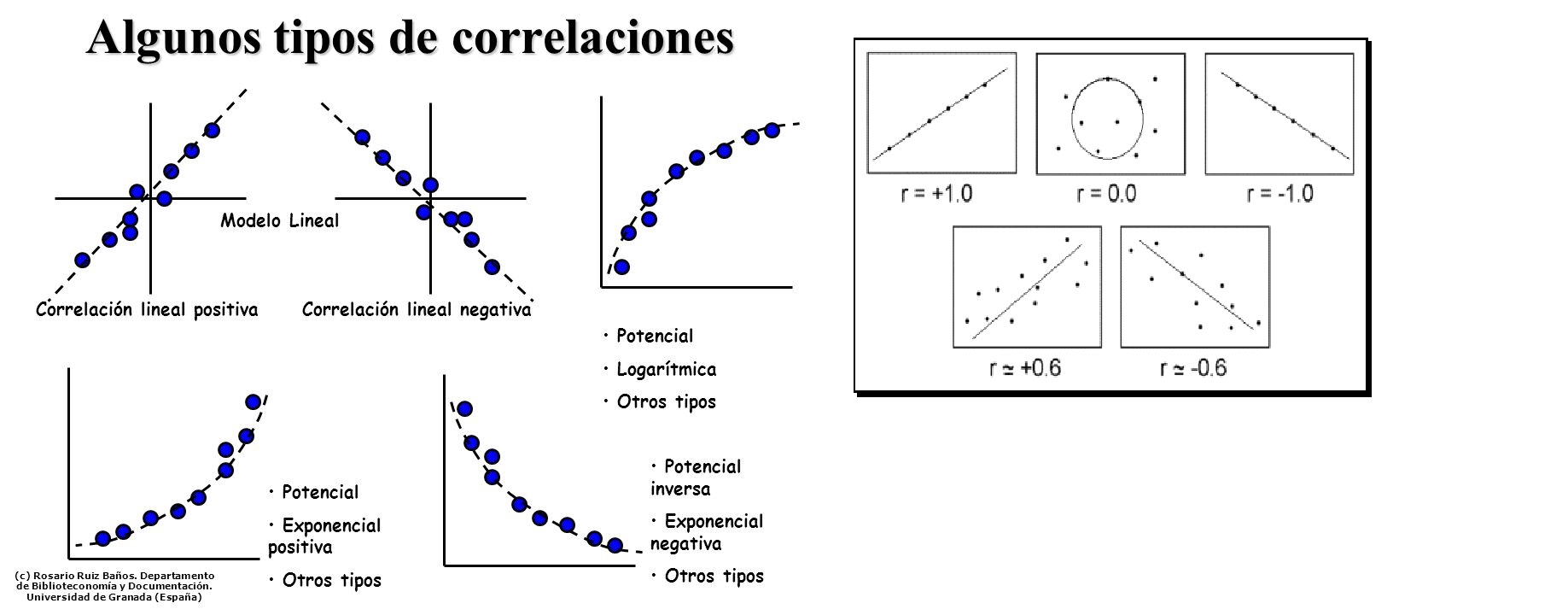
6. Correlación
La correlación indica la fuerza y la dirección de una relación lineal entre dos variables. Se considera que dos variables cuantitativas están correlacionadas cuando los valores de una de ellas varían sistemáticamente con respecto a los valores de la otra: si tenemos dos variables (A y B) existe correlación positiva entre ellas si al disminuir los valores de A lo hacen también los de B y viceversa y tenemos una relación negativa si al disminuir los valores de A aumentanlos de B o viceversa. La correlación entre dos variables no implica, por sí misma, ninguna relación de causalidad.
correlacion
La herramienta que sirve para visualizar la relación entre dos variables se llama diagrama de dispersión
El coeficiente de correlación de Pearson es una cantidad que mide la correlación entre variables.
\[ r = \frac{n \sum{XY}-(\sum{X}\sum{Y})}{\sqrt{ [n \sum{x^2}-(\sum{x})^2 ][n \sum{y^2}-(\sum{y})^2 }]} \]
Material de apoyo
Cálculo de medidas de tendencia central y de variabilidad. http://mucioosorio.github.io/probabilidad/doc/tendencia_central_variabilidad.pdf
Construcción de histograma. http://mucioosorio.github.io/probabilidad/doc/Histograma.pdf
Cuarteto de Anscombe
https://es.wikipedia.org/wiki/Cuarteto_de_Anscombe
El cuarteto de Anscombe comprende cuatro conjuntos de datos que tienen las mismas propiedades estadísticas, pero que evidentemente son distintas al inspeccionar sus gráficos respectivos.
Cada conjunto consiste de once puntos (x, y) y fueron construidos por el estadístico F. J. Anscombe. El cuarteto es una demostración de la importancia de mirar gráficamente un conjunto de datos antes de analizarlos.
Para los cuatro conjuntos de datos:
| I | II | ||
|---|---|---|---|
| x | y | x | y |
| 10.0 | 8.04 | 10.0 | 9.14 |
| 8.0 | 6.95 | 8.0 | 8.14 |
| 13.0 | 7.58 | 13.0 | 8.74 |
| 9.0 | 8.81 | 9.0 | 8.77 |
| 11.0 | 8.33 | 11.0 | 9.26 |
| 14.0 | 9.96 | 14.0 | 8.10 |
| 6.0 | 7.24 | 6.0 | 6.13 |
| 4.0 | 4.26 | 4.0 | 3.10 |
| 12.0 | 10.84 | 12.0 | 9.13 |
| 7.0 | 4.82 | 7.0 | 7.26 |
| 5.0 | 5.68 | 5.0 | 4.74 |
Realice un análisis de los 4 conjuntos de datos de Ascombe.